随着深度神经网络(DNN)的快速发展和数据集规模的持续增长,分布式深度神经网络训练系统在梯度同步过程中面临通信瓶颈。梯度压缩技术能够极大程度上减少通信开销,但是由于只传输压缩的梯度,会造成模型准确率的损失。为了确保模型准确率和收敛性能,通常将原始梯度与压缩梯度的差值(残差)存储在GPU内存中以补偿损失。然而,残差通常会在训练过程中产生显著的GPU内存开销,限制了集群可训练模型的大小。
为了解决这个问题,信息存储系统教育部重点实验室硕士生郑欣觉,博士生明章强,在导师胡燏翀教授的指导下,提出了ResiReduce显存优化方法,其主要思想是利用模型准确率和残差显存占用的权衡关系,通过很小的精度损失达到显著降低残差显存占用的目的。实验观察表明,类型相同并且相邻的多个残差层通常具有相似的密度分布。基于此,ResiReduce通过层间和层内两种方式缩减残差:首先在具有相同结构的相邻层间重用残差平均值,并提出对残差进行加权平均来提高精度;进一步通过简单的维度压缩方法减少某些特定层内的残差,并提出二维行列稀疏化压缩方法以提高训练精度。
在本地和云集群上的实验结果表明,ResiReduce能够将模型状态的显存占用减少至多15.7%,同时保持了模型的准确性和训练吞吐量不受影响。此外,ResiReduce可以很好地适用于各种梯度压缩方法和梯度压缩率。
该研究工作题为“Saving Memory via Residual Reduction for DNN Training with Compressed Communication”发表在中国计算机学会推荐的B类国际学术会议International European Conference on Parallel and Distributed Computing (Euro-Par 2025)。该研究工作得到了国家自然科学基金面上项目(No. 62272185)和深圳市科技计划项目(No. JCYJ20220530161006015)的支持。
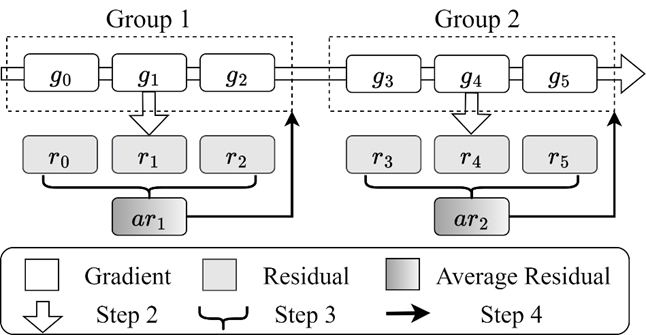
图1 残差平均值重用过程示例
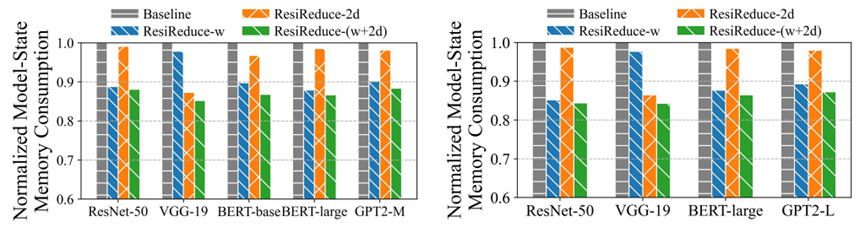
图2 本地和云集群中归一化模型状态显存开销

 分享文章
分享文章