近日,实验室博士生周恒论文ODLPIM: A Write-Optimized and Long-Lifetime ReRAM-Based Accelerator for Online Deep Learning、博士生彭周旋的论文“AGDM:An Adaptive Granularity Data Migration Strategy for Hybrid Memory Systems”、博士生袁莹的论文“TPP: Accelerate Application Launch via Two-Phase Prefetching on Smartphone”、博士生张鑫晏的论文“Multidimensional Features Helping Predict Failures in Production SSD-Based Consumer Storage Systems”被Design, Automation and Test in Europe Conference(DATE 2023)录用。
存算融合(Processing-in-Memory,PIM)架构因其原位计算特性在DNN场景能实现高能效计算,是有望解决“存储墙”的瓶颈的非冯诺伊曼体系结构。在针对DNN加速的PIM架构中,大部分现有工作局限于传统的离线批训练(offline batch learning,OBL),这需要在训练前获取到完整的数据集。然而在现实世界中,数据往往是以序列的形式顺序到达,甚至存在概念漂移的问题,这会导致离线批训练的模型不可用,需要高昂的重训练开销。在线学习(Online deep learning,ODL)能对流式数据进行学习并保持模型的持续演化,最大程度地保持模型的可用性,在流式数据场景中相比OBL避免了重训练开销,在PIM架构中更能节省重训练所需的能耗以及单元磨损。在PIM系统中对百万级别的大规模流式数据进行在线学习会存在巨量的权重更新,一方面频繁的权重更新会对忆阻器单元造成大量的擦写,另一方面数据规模之大导致整个PIM系统中的写入不均衡性被放大,“短板效应”凸显。
根据对忆阻器阵列的磨损统计结果,发现在忆阻器阵列中进行训练时,主要有两个原因导致磨损不均衡:u如图1a所示,对于量化后的权重,其LSB和MSB的更新频率不一样,导致不同字线之间的磨损不均衡;v如图1a所示,在权重更新过程中,量化会丢弃部分权重极小的更新,因此会导致权重矩阵中不同权重值的更新不均衡。为了解决忆阻器阵列的磨损不均衡问题,现有方案都局限于阵列内部进行磨损均衡(如图1b所示),然而整个PIM系统的寿命是由最差的阵列所决定,因此亟须解决PIM系统级的磨损不均衡问题。
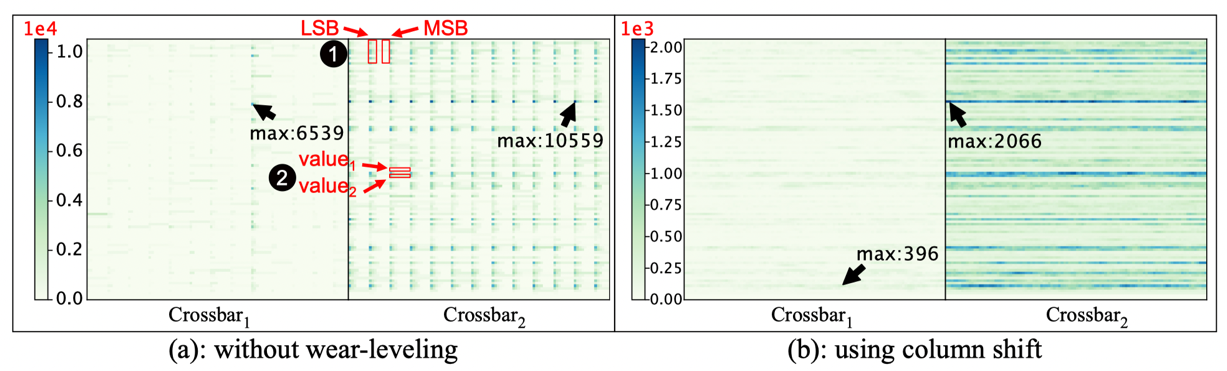
图1 系统中两个Crossbar阵列使用列移位前后的写分布对比(使用8bit量化权重和1bit忆阻器单元)
为了解决在线学习在PIM架构中的寿命问题,信息存储与光显示功能实验室博士生周恒,在冯丹教授、童薇副教授的指导下提出了针对在线学习的PIM架构,通过软硬协同优化实现高寿命。在软件层面提出写优化权重更新策略(WARP),根据HBP在线学习算法不同层的贡献率分布变化减少非关键层的权重更新,具体地,当隐藏层的贡献率低于阈值时,限制该层的权重更新,实现写减少。在硬件层面提出基于表的阵列间磨损均衡策略(TIWL),通过构建映射表对系统中的阵列进行磨损均衡,以较小的硬件开销最大化系统级磨损均衡。具体地,我们为每个Crossbar阵列配备一个寄存器记录该阵列在磨损均衡间隔内所有单元的写入总和(IWC),以此表示该阵列在当前磨损周期间隔内的写入热度。同时,我们使用TWC来表示一个阵列整个生命周期内的写入总量,并将其存储在非易失的专用阵列中。每次磨损均衡周期末尾,根据逻辑阵列ID(LAID)的IWC进行排序,将“热”的逻辑阵列重新映射到“冷”的物理阵列中,然后将IWC置0,由于磨损均衡调度可以和权重更新重叠,因此可以减少磨损调度所带来的额外写。此外,TIWL与现有阵列内磨损均衡方案是正交的,通过搭配使用可实现进一步的磨损均衡效果提升。最终实验结果表明,相比没有使用WARP,使用WARP后能平均减少15.25%(最高24%)的权重更新,平均延长系统寿命达9.65%(最高26.81%),累计错误率的上升几乎忽略不计(0.31%)。通过结合WARP和TIWL,系统整体寿命提高平均12.59倍(最高17.73倍)。
该研究于2022年11月被IEEE Design, Automation and Test in Europe Conference(DATE 2023)录用,题为“ODLPIM: A Write-Optimized and Long-Lifetime ReRAM-Based Accelerator for Online Deep Learning”。DATE是计算机体系结构领域重要的国际学术会议之一。该工作得到了国家自然科学基金的支持(No. 61832007, No. 61821003,No. 62172178)。
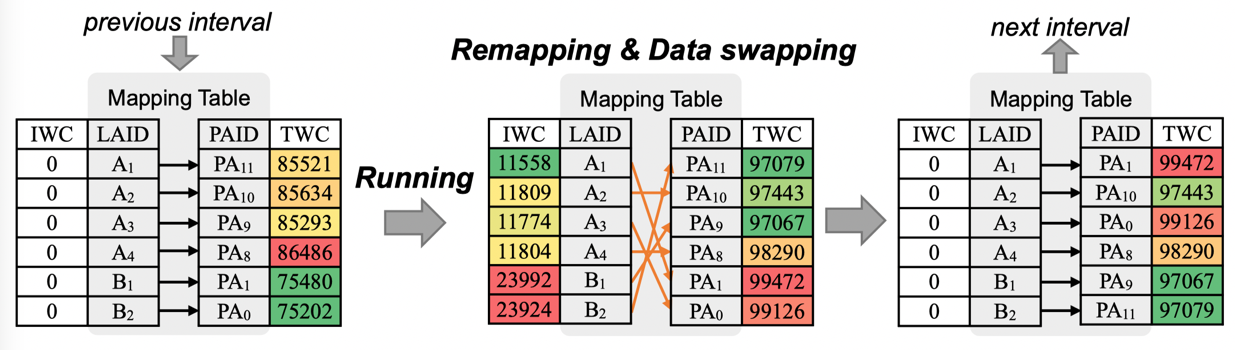
图2 基于表的阵列间磨损均衡运行过程以及映射表结构(红色表示磨损较高,绿色表示磨损较低)
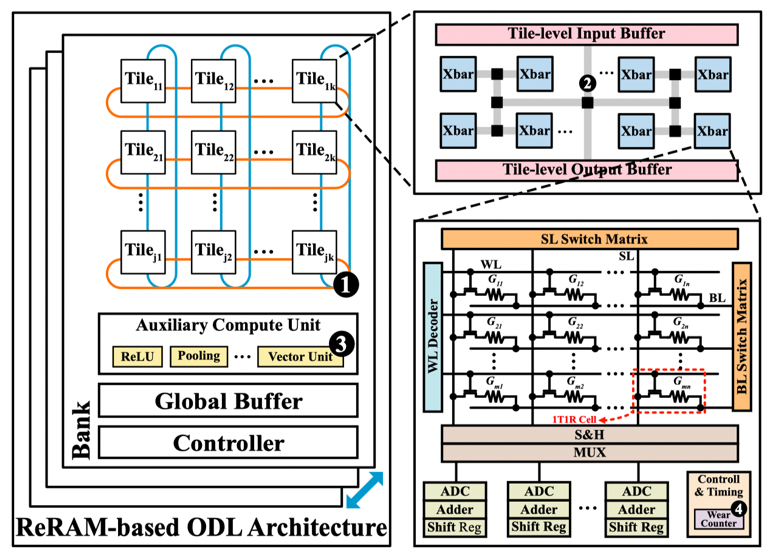
图3 ODLPIM架构概览
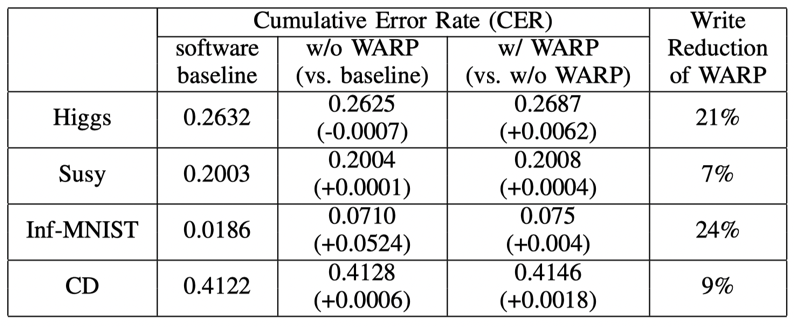
图4 WARP方案累积错误率(CER)和写减少对比
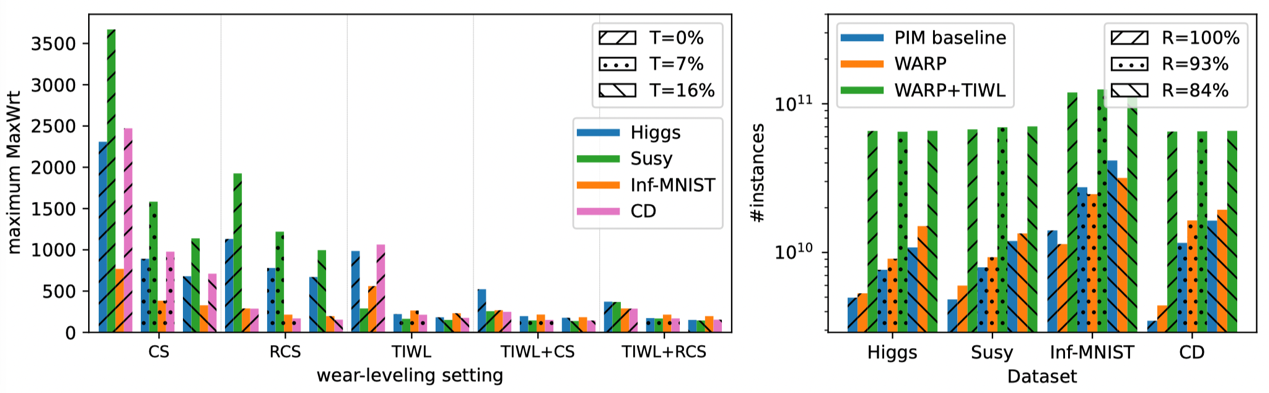
图5(a)不同磨损均衡方案和容忍度T下最大MaxWrt对比;(b)不同R值下WARP和TIWL的寿命延长效果
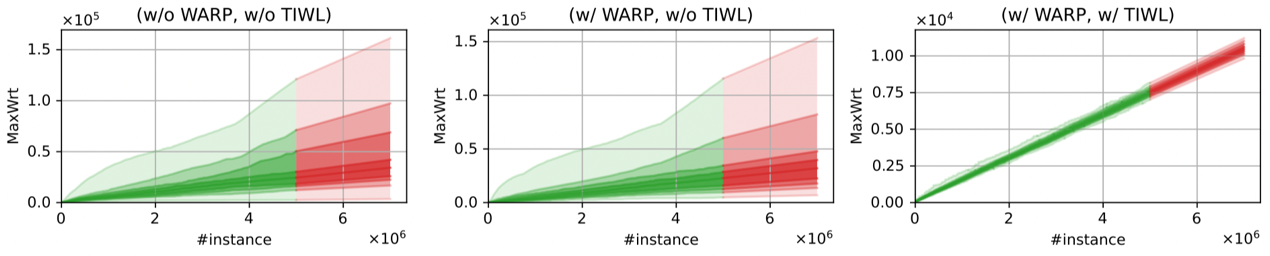
图6 阵列最差单元写入MaxWrt的分布变化(绿色为实际结果,红色为线性预测结果,数据集为Higgs)
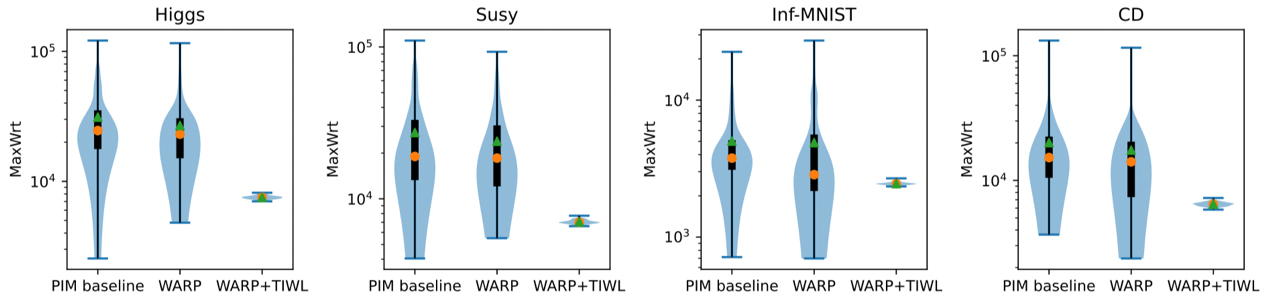
图7 训练结束时系统中所有Crossbar阵列的最差单元写入MaxWrt分布图(绿三角为平均值,橙圆形为中位数)
混合内存系统通过组合使用不同的内存技术,扬长避短,从而能够同时满足性能、能耗、容量、成本等多方面的需求。因此,应用混合内存系统已成为解决现代应用日益多样化内存需求的主流方法。由于不同内存技术存在性能差异,必须采用合适的数据迁移方法将热数据迁移至快速内存以提高整体性能。然而,现有的数据迁移方案只关注于识别热数据和迁移决策,忽视了迁移粒度这一关键因素,导致现有设计在大部分负载下都无法达到最佳性能。
实验室博士生彭周旋在冯丹教授,陈俭喜副教授等的指导下,提出了访问模式感知的自适应粒度数据迁移方案AGDM。AGDM能够在运行时跟踪内存的访问模式,并根据访问模式采用最合适的迁移粒度。为了支持在具有不同访问模式的的内存区域上启用局部迁移粒度,AGDM设计了独特的映射-迁移解耦合的数据组织结构。针对不同的访问模式,AGDM能够自适应地采用三种不同的迁移模式:1)定长自适应模式,2)空间足迹预测模式,3)透明模式。 与当前最先进的方案相比,AGDM的整体性能优化了20.06%,并且降低了29.98%的能耗。
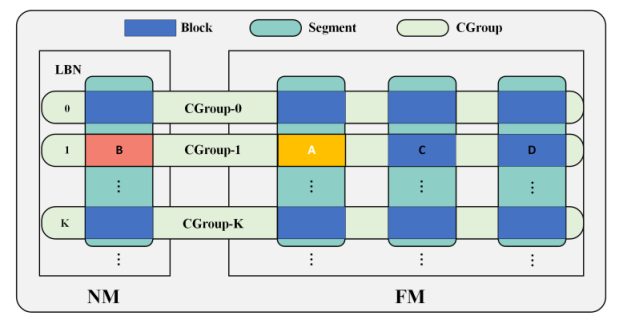
图8 AGDM映射-迁移解耦合数据组织结构示意图
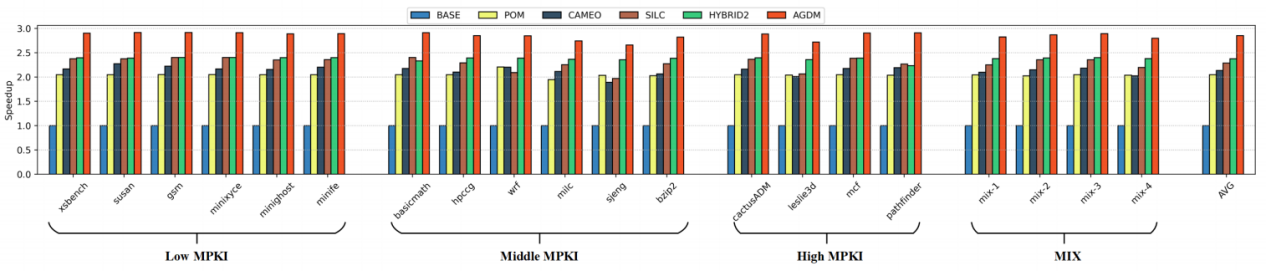
图9 整体性能对比
在交互式移动设备上,快速的App启动对用户体验至关重要,这是厂商永恒的追求之一。缺页异常是导致App启动延迟过长的关键因素。预读是当前减少App启动期间缺页异常的方法,在App启动前,预读目标App即将要访问的所有页,可以有效提升App启动速度,但这种预读方式需要在短时间内读入大量内存(几百MB),但这种方案依赖App预测算法的准确性,若预测结果错误,则严重降低内存的使用效率;在应用启动期间预读App即将要访问的页,可以有效提高内存利用率,但现有预读方案不感知页的访问顺序,导致严重的访问-预取顺序翻转问题,App启动加速效果有限。
博士生袁莹在谭支鹏教授的指导下提出了一种两阶段预读方案(two-phase Prefetching schema, TPP),以极少的内存开销有效加速App启动。TPP通过两个阶段进行预读:1)在App启动前,TPP基于长短期记忆网络(Long Short-Term memory, LSTM)进行高准确度的App预测,预读少量但重要的关键启动页,以提高预读的内存使用效率;2)在App启动期间,TPP通过一种顺序感知的滑动窗口方法预读其余普通启动页,解决了访问-预取顺序翻转问题,显著降低了App启动延迟。在Google Pixel 3上的实验结果表明,与目前最先进的方法相比,TPP最高减少了52.5%的App启动时间,平均减少了37%,并且目标App启动前平均预取数据量仅为1.31MB。
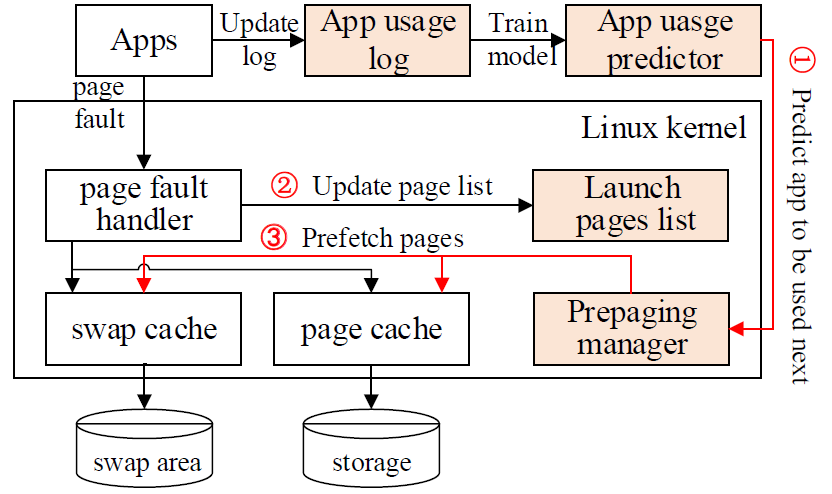
图10 整体架构
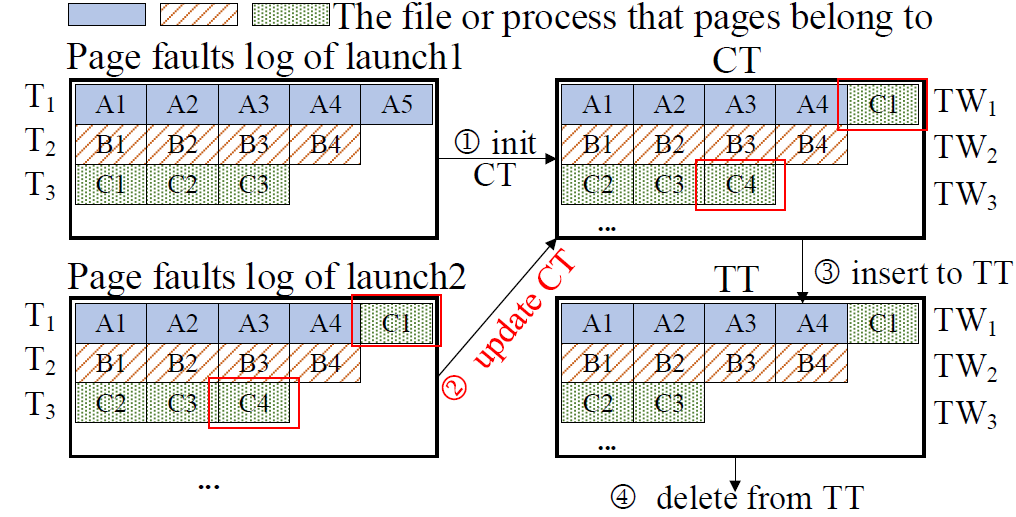
图11 预读数据管理
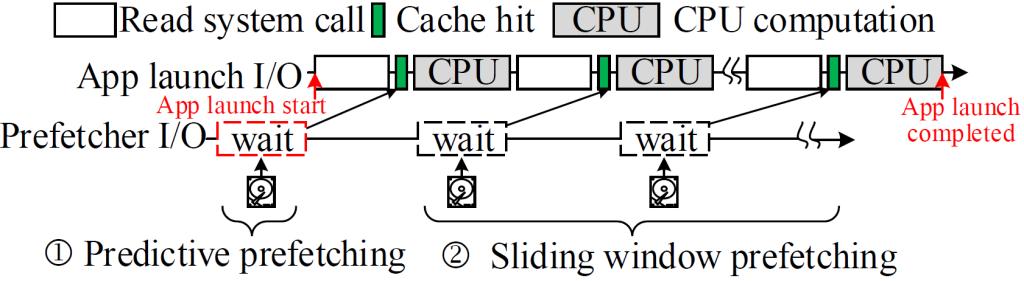
图12 两阶段预读
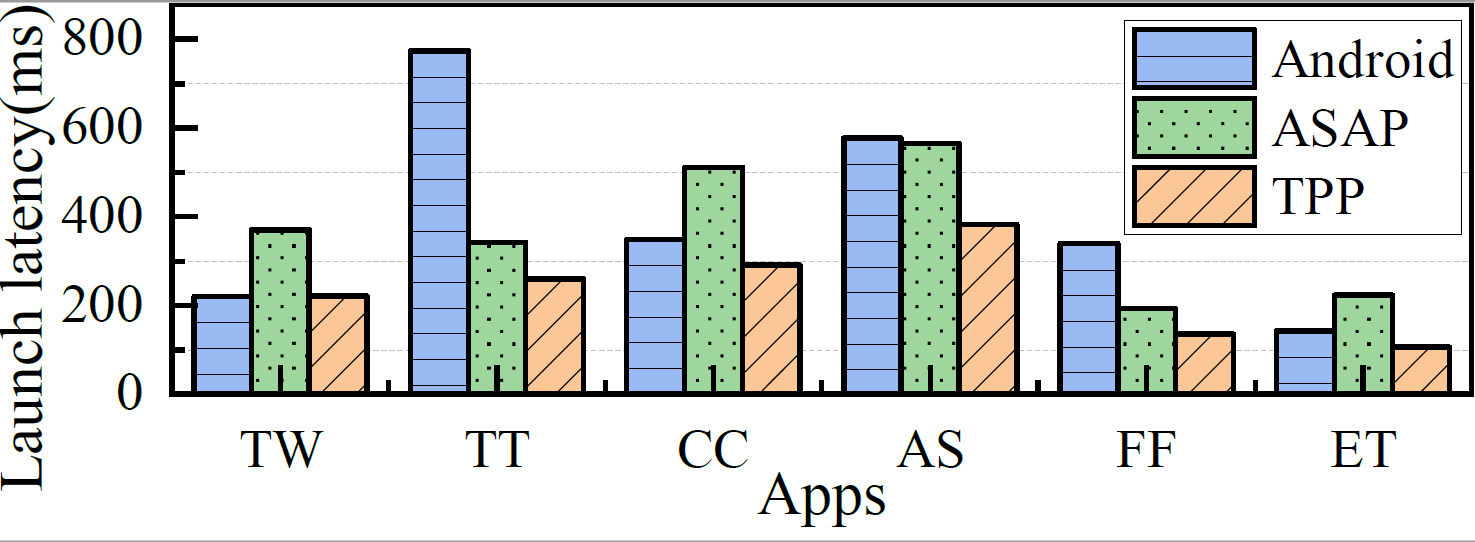
图13 App启动加速效果测试
性能更优的SSD正逐步替代HDD,然而SSD失效仍会严重导致数据丢失和业务中断。因此基于AI的故障预测技术被用于提高系统可靠性及可用性。当前主流技术多聚焦于面向企业级用户的大规模、中心化部署、易采样的企业存储系统(ESS);研究的存储设备多聚焦于能7*24h提供稳定服务的企业级存储盘;采集的健康状态特征多覆盖于SMART信息、负载信息、错误日志及位置信息等。消费级用户的数据同样重要,但该存储市场受到的关注较少。同时其特有的跨地域分散性、用户使用习惯多样性、存储设备异构性、采样复杂性、可用特征单一性等导致现有技术方案在消费级存储系统(CSS)中预测效果不佳。
实验室博士生张鑫晏在冯丹教授,谭支鹏教授等的指导下,提出了基于多维特征的SSD故障预测方案MFPA。通过分析CSS中真实海量SSD的状态数据发现了与其故障相关的多维特征序列SFWB;设计基于间隔感知的滑动窗口机制及均值填充技术解决采样数据的不连续性和故障时间点的难确定性;采用基于时间点的样本分割及基于时序的交叉验证技术提高模型的泛化能力;基于多维特征结合多种算法构建有效的故障预测模型。测试结果表明MFPA较现有方案,召回率和误报率得到4%和86%的优化,对建模算法、设备厂商、提前时间及迭代周期均具备不敏感特性。
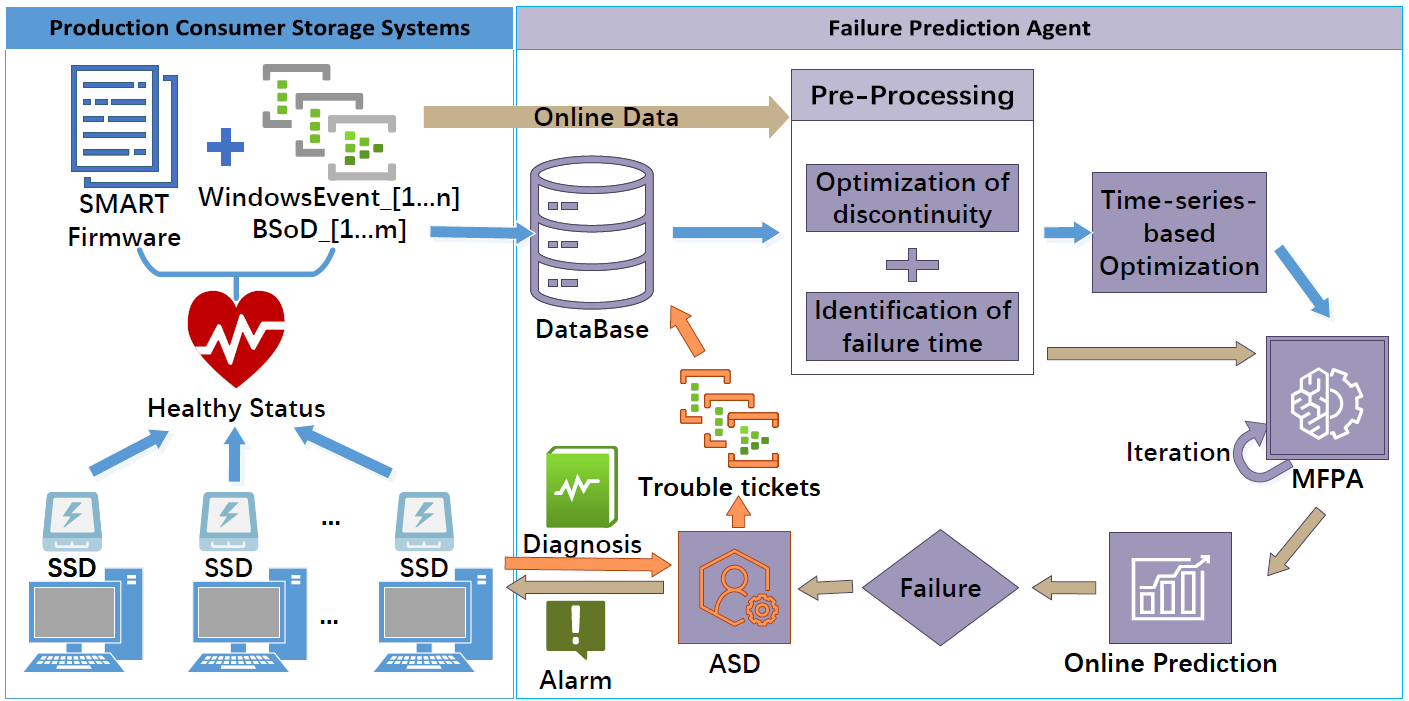
图14 方案架构
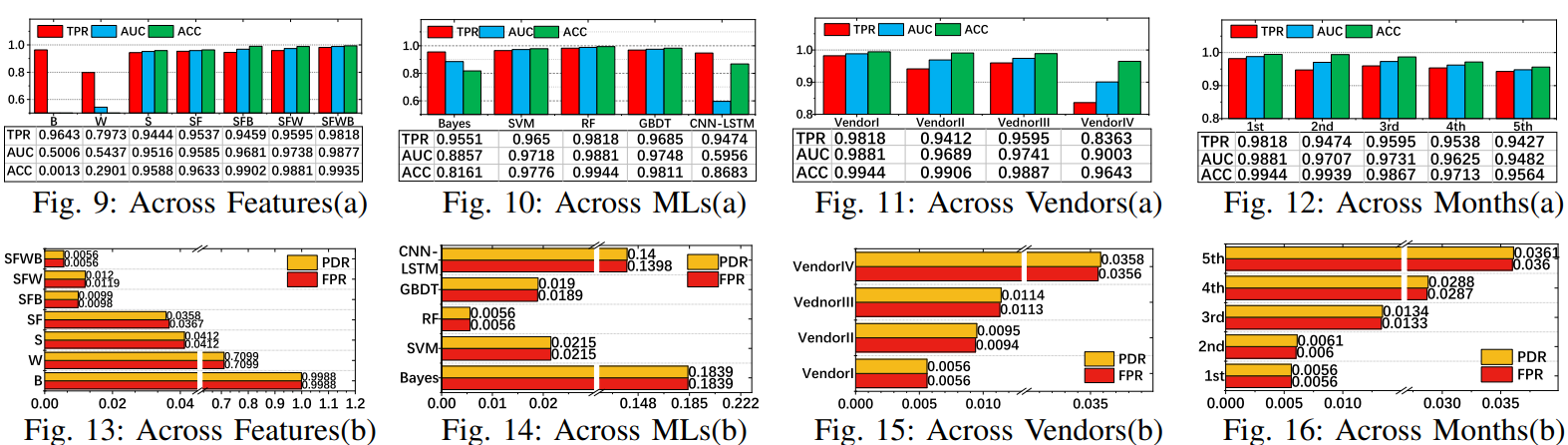
图15 整体性能对比

 分享文章
分享文章