存算一体(Computing-in-Memory,CIM)架构能通过原位计算有效加速矩阵向量乘法(Matrix-vector multiplication,MVM),减少数据搬运的开销,有望解决传统冯诺伊曼体系结构的“存储墙”瓶颈。现有软件层面的通信优化工作主要通过精心设计静态的数据布局来减少通信距离;硬件层面的磨损均衡和错误处理工作通过动态调度来提高系统寿命,但却导致数据布局随机化,增加通信距离。
为了平衡通信性能和可靠性,同时让现有CIM编译器与动态调度相协调,信息存储与光显示功能实验室博士生周恒,在冯丹教授、童薇副教授的指导下提出了抗无序存算转换层(Disorder-Resistant Computation Translation Layer,DRCTL)来提高忆阻器CIM架构的寿命和性能,如图 1所示,其包含三个部份:(1)地址转换,解决编译器与动态调度的不兼容问题;(2)提高可靠性的动态调度策略,我们提出了层次化磨损均衡策略(Hierarchical wear-leveling,HWL),通过提高调度粒度来减少通信量;(3)动态调度的通信优化。我们提出了数据布局感知的选择性重映射策略(Data layout-aware selective remapping,LASR),利用数据依赖性,帮助动态调度方法提高通信局部性并降低延迟。实验证明,与不使用磨损均衡相比,使用HWL的CIM系统寿命延长了100.3-205.9倍。即使HWL与最新的磨损均衡策略(TIWL)相比提升寿命的效果略低,但仍可以支持神经网络持续训练6年(不使用磨损均衡策略仅支持12天持续训练)。使用LASR优化 HWL后,执行周期数、能耗、片上NoC和片外NoC访问次数分别平均减少26.91%、26.88%、36.41% 和 80.62%。
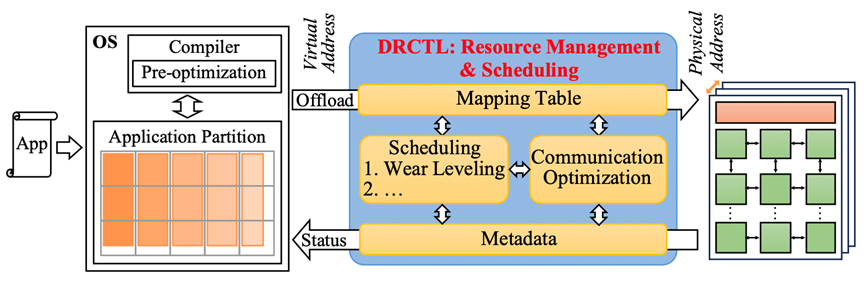
图 1. DRCTL概览图
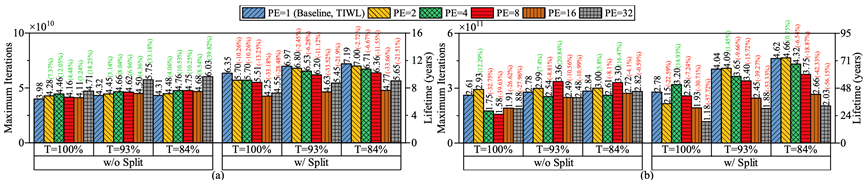
图 2. 在 (a) Higgs数据集和 (b) CD1数据集下使用HWL后寿命延长的比较。括号中显示了HWL 与具有相同T值和数据分割策略的TIWL相比寿命增加/减少的百分比。
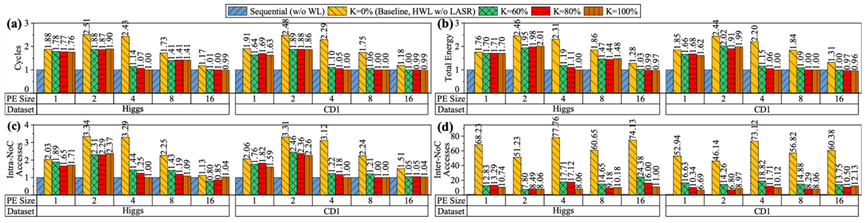
图 3. 使用PUMA模拟器对不同动态调度配置NN推理的(a)执行周期、(b)能耗、(c)片内NoC通信次数和(d)片外NoC通信次数比较。
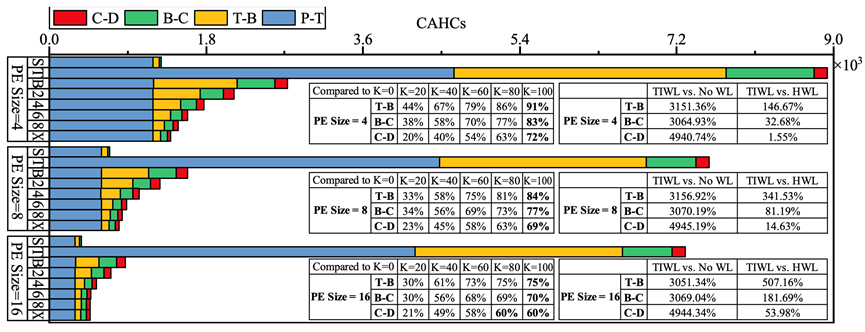
图 4. 在Higgs数据集中NN训练的跨架构层次通信(CAHC)比例细分图。S(顺序方案,不使用WL)、T(TIWL)、B(Baseline,不使用LASR的HWL)、2(K=20%)、4(K=40%)、6(K=60%)、8(K=80%)、X(K=100%)。左表:与 HWL 相比,LASR 的CAHC减少比例。右表:与不使用WL和HWL相比,TIWL的CAHC增加比例。
该研究工作题为“DRCTL: A Disorder-Resistant Computation Translation Layer Enhancing the Lifetime and Performance of Memristive CIM Architecture”,在2024年国际计算机体系结构旗舰会议MICRO(IEEE/ACM International Symposium on Microarchitecture,CCF A类)上获录用。该研究工作得到了国家重点研发计划项目(2023YFB4502100)、国家自然科学基金项目(61832007)、预研项目(31511090201)、国家自然科学基金青年科学基金项目(62302179)以及华中科技大学交叉研究支持计划(2023CJYJ042)的支持。

 分享文章
分享文章