近日,实验室博士生周海的论文“Multi-level Forwarding and Scheduling Repair Technique inHeterogeneous Network for Erasure-coded Clusters”、周洋的论文“ASLDP: An Active Semi-supervised Learning method for Disk Failure Prediction”、于金玉的论文“CERES: Container-Based Elastic Resource Management System for Mixed Workloads”、胡静的论文“Parallel Multi-split Extendible Hashing for Persistent Memory”、杜静文的论文“Fast and Consistent Remote Direct Access to Non-volatile Memory”、雷梦雅的论文“Crash-Consistency-Aware Encryption for Non-Volatile Memories”和程良锋的论文“Coupling Right-Provisioned Cold Storage Data Centers with Deduplication”被International Conference on Parallel Processing(ICPP 2021)正式录用。
纠删码提供了一种存储高效的冗余机制,用于维护存储集群中的数据可用性保证,但在故障修复中也会导致较高的网络带宽和恢复时间。现有的研究旨在减少异构网络中的修复时间,但由于集群网络的异构性,恢复时间总是受到低带宽链路的限制。
实验室博士生周海在冯丹教授、胡燏翀教授等的指导下,提出了面向单节点的多级转发修复技术SMFRepair和多节点的调度修复技术MSRepair。SMFRepair有两个关键步骤,首先根据条带中节点之间的带宽选择耗时最少的修复解决方案。然后,它使用条带外的空闲节点绕过带宽最低的链路,以进一步减少时间,同时避免网络拥塞和竞争。MSRepair找到了一种恢复解决方案,该解决方案调度多节点的并行修复,并从尽可能大带宽的链路传输数据,主要目标是最大限度地降低恢复时间。大规模Mininet仿真和Amazon EC2真实实验表明,与已有的最新进展PPT修复技术相比,单节点恢复时间最多可减少36.65%,多节点恢复时间最多可减少55.10%。

磁盘故障一直是数据中心迫切需要解决的问题,一旦发生故障就有可能导致数据丢失。当前的研究工作主要通过收集大量的已标记样本,采用监督学习方式进行离线训练。然而,这种离线建模方法已经不再适用于当前大数据环境中的磁盘故障预测任务。在真实大规模数据中心的场景下,大多数方法没有考虑在模型训练阶段标记值可能较难获取,或者已标记值不完全准确等等。这些问题限制着监督学习和离线建模在磁盘故障预测领域的进一步应用。
信息存储及应用实验室博士生周洋,在王芳教授的指导下,提出一种主动半监督磁盘故障预测方法——ASLDP。通过分析数据在磁盘生命周期上的特点,对于那些有准确可信的标记样例,ASLDP进行主动学习建模,剔除冗余度较大并选择信息量充足的样例;而对于那些没有很高可信度或者无标记样例,ASLDP结合半监督学习建模进行预标记,并和主动学习一起增强模型的泛化能力。对来自真实场景下的磁盘数据进行测试,实验结果证实了上述方法能够很好解决大数据环境下数据冗余和样例标记缺失等问题。该文相比较之前的工作,是首次提出采用主动学习和半监督学习进行建模,这和之前采用监督学习有很大的不同。
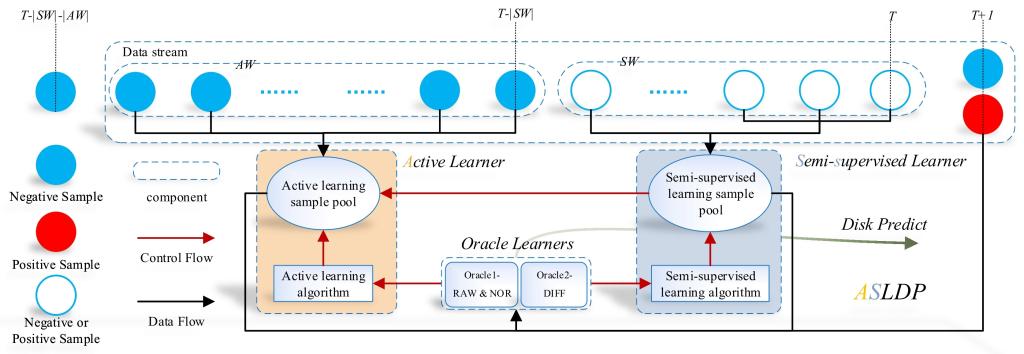
物联网、机器学习等新兴技术的广泛应用增加了负载的多样性,使得数据中心在任务调度和资源管理方面面临很大的挑战。以往企业使用专用集群或资源预留的方法来保证应用的服务质量,但是这些方法会导致负载不平衡,集群资源利用率低等问题。为了运营降低成本,企业采用混合负载部署的方法将多种工作负载部署在同一集群中。阿里巴巴、微软必应和谷歌都使用该方法将批处理作业与对延迟敏感的服务一起部署在集群中。虽然负载不同的资源需求使得部署混合负载部署成为可能,但是该方法使得负载面临资源竞争和性能干扰等问题,严重影响应用的服务质量。现有解决方案通过从批量作业中抢占资源来满足延迟敏感型任务的资源需求,进而保证敏感延迟服务的服务质量。但是直接抢占批处理任务资源的方式会导致批处理作业有很大的性能损失。此外,谷歌、阿里巴巴等企业开源的集群跟踪数据显示集群中许多任务并没有充分利用分配给它们的资源,从而导致集群资源浪费。
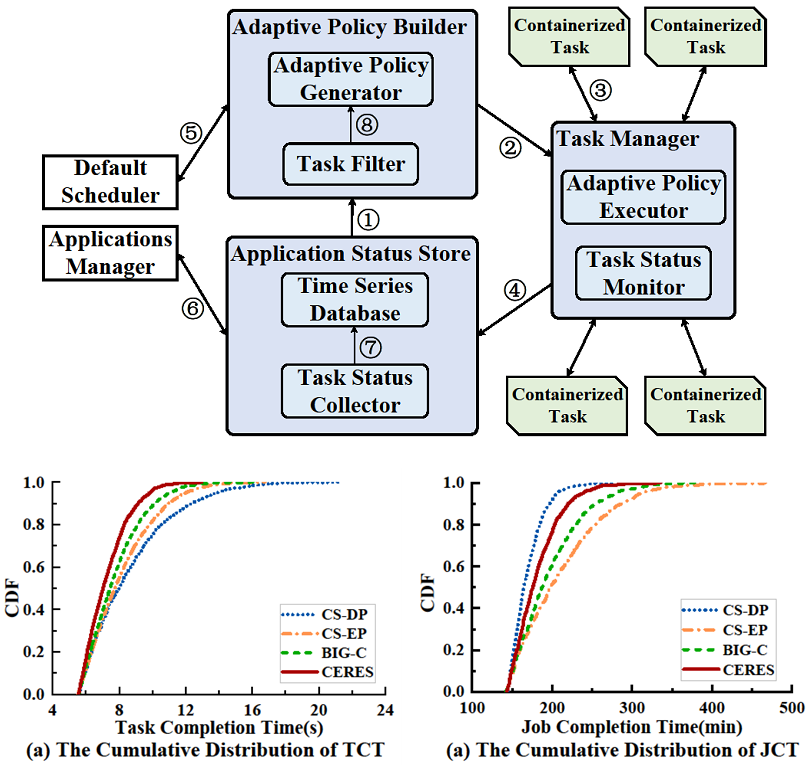
实验室博士生于金玉,在冯丹教授、童薇副教授的指导下,设计实现了一个面向混合负载基于容器的弹性资源管理系统CERES。CERES通过充分利用任务的冗余资源来保证面向用户的延迟敏感型应用的服务质量,减少因资源抢占对批处理作业产生的性能损失。CERES首先从运行的任务中筛选出批处理作业的资源冗余任务和延迟敏感型服务中的Straggler任务,如果集群空闲资源充足则对Straggler任务资源扩展,否则需要从资源冗余任务中进行资源回收。资源回收之后,如果集群中的空闲资源仍无法满足延迟敏感型新任务的资源需求以及Straggler任务的扩展资源需求,则需要对批处理作业进行资源抢占操作。我们基于Hadoop YARN部署实现了CERES并对其进行了性能测试,测试结果证明CERES不仅可以保证延迟敏感型服务的QoS、减少对批处理作业的性能影响,还可以提升集群的资源利用率。

新兴的持久性内存可提供接近DRAM的性能和类似磁盘的耐用性,有望取代DRAM或者作为DRAM的补充。随着Intel在2019年发布第一款商用傲腾持久性内存更是加剧了这种趋势。然而,许多基于DRAM设计的数据结构,如哈希表和B树,对于持久性内存来说是次优的。研究表明,现有的哈希方案受限于并发控制锁的高开销和重新哈希导致的大量数据移动开销,不能充分发挥持久内存的优势。
实验室博士生胡静,在陈俭喜副教授的指导下提出了一种无锁并行多分裂可扩展哈希方案,称为PMEH。为了减少数据移动,PMEH使用多分裂而不是传统二分裂去扩展哈希表,同时采用逐步分裂的方式,减少了多分裂申请更多内存导致的申请开销和延迟。为了减少段的锁开销,PMEH将目录分成不同的分区,并将每个分区只与一个线程绑定,实现了段无锁。为了减少目录的锁开销,PMEH引入额外的目录数组,使得某个线程导致的目录扩展不会影响其它线程。评估结果表明,与当前其他最先进的哈希方案相比,PMEH的插入性能提高了1.38倍,删除性能提高了1.9倍,同时减少了52%的额外写入。此外,PMEH还确保了即时恢复。

PMEH方案整体框架
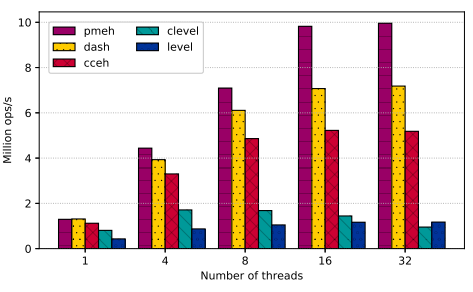
插入性能对比
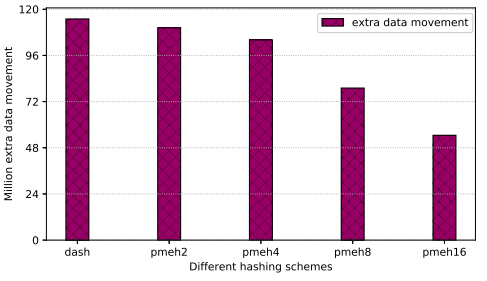
额外写减少
非易失存储器(Non-Volatile Memory, NVM)具有字节可寻址、高密度的特性,并且其同时具有接近DRAM级别的访问延时和非易失性。RDMA技术可以直接访问远端内存而不经过内核,去除了多次内存拷贝开销,因此能提供高性能。单边RDMA还能旁路远端CPU实现卸载。此外,大规模数据中心应用需要快速访问海量持久性数据。因此结合RDMA和NVM构建分布式存储系统已经成为一种趋势。由于NVM使得易失性-持久性边界为CPU cache和NVM之间,需要控制CPU缓存行的写顺序和基于拷贝机制的策略来保证系统崩溃一致性。但是现有RDMA write不具有远端持久性语义,客户端收到确认时只保证数据到达远端网卡。如果系统在数据被完整刷回到NVM前出现崩溃,将导致数据不一致。此外,RDMA write的完成状态服务器不可知,现有基于该原语的Client-active写策略在数据完整持久化到NVM前修改元数据,使不一致数据暴露。
实验室博士生杜静文,在王芳教授、冯丹教授的指导下,发现现有设计牺牲读性能或写性能来保证基于RDMA的NVM存储系统的崩溃一致性。基于此设计实现了既能保证高的读写性能又能保证数据一致性的系统eFactory。eFactory采用log-structured方式进行数据的异地更新,同时将数据的多个版本链接成链表,以便出现崩溃(特别是多线程并发访问同一对象)时可以利用前面的完整版本恢复到一致的状态。其利用单个后台线程来进行数据完整性验证和持久化,以便尽量将完整性校验开销和数据持久化开销从读写关键路径上去除。此外,为了充分利用单边RDMA read的高性能同时保证数据一致性,eFactory提出了混合读策略。该策略先乐观地使用单边RDMA read原语进行读操作,通过每个对象中嵌入的持久性标识位来判断该对象版本的一致性状态,如果不一致则转换为RPC+RDMA read策略。实验表明,eFactory的读性能比现有牺牲读换取一致性的方案提升了1.24x-1.96x,写性能比现有牺牲写换取一致性的方案提升了0.42x-2.85x。
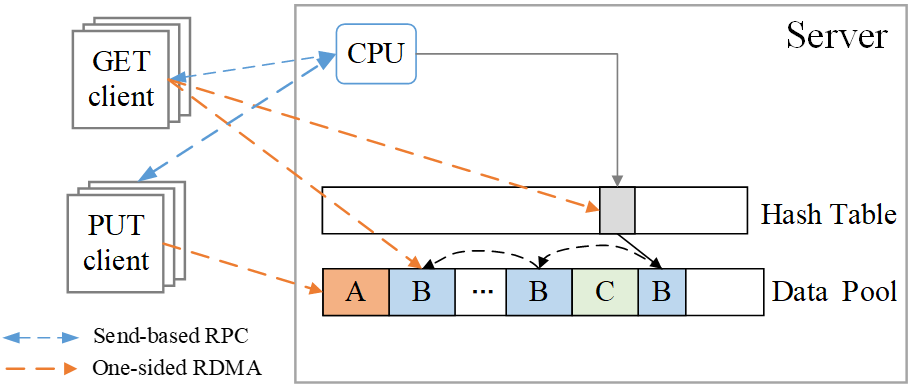
eFactory整体架构
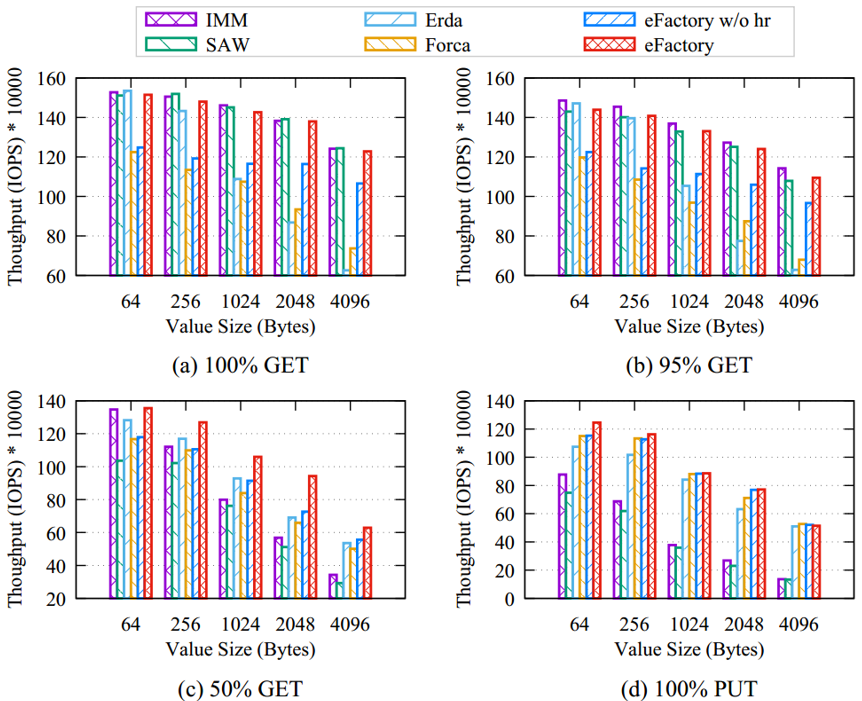
不同值大小的端到端性能比较

不同客户端数量的吞吐比较
快速发展的新型非易失存储器件NVM正逐步占据内存市场。然而,NVM也给内存加密机制的设计带来了新的挑战。非易失性存储要求在加密NVM中同时保证数据和加密元数据计数器的崩溃一致性,确保系统断电后数据能正确解密和恢复。然而,这将导致不可接受的写流量:为了正确恢复,一次数据更新将导致4次NVM写,包括一次日志写、一次日志计数器写、一次数据写和一次数据计数器写。加密NVM中,如何实现高效的崩溃一致性和加密方案是有待研究的问题。
实验室博士生雷梦雅、硕士生李凡,在王芳教授的指导下,设计实现了崩溃一致性感知的NVM加密方案,CCAE。CCAE挖掘了现有NVM系统中数据和日志的访问特性,设计了对应的计数器加密、持久和恢复方案。具体而言,利用NVM中事务日志区域的追加写特性,CCAE提出了针对日志的共享计数器加密方案SCO,极大的减少了日志区域对应的计数器的数量和持久化开销。同时,利用NVM中未提交事务本地数据区域数据可丢弃的特性,CCAE设计了针对数据的延迟计数器持久化加密方案DCP,充分融合和吸收了数据计数器持久化导致的NVM写操作,提升了系统性能。

共享计数器优化SCO中日志计数器写请求的减少
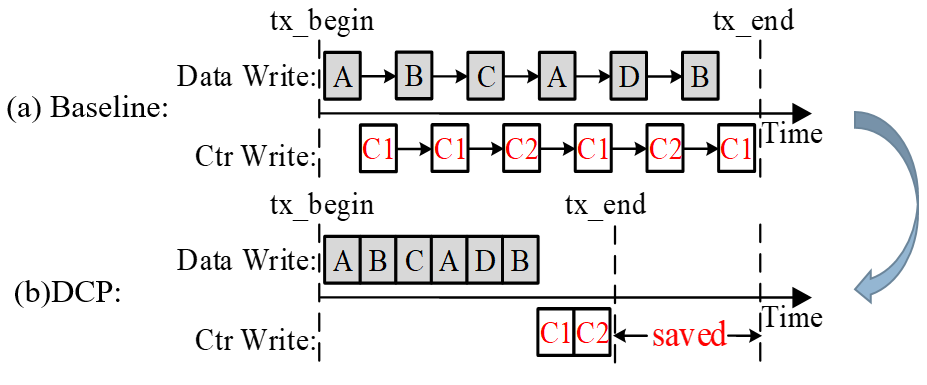
延迟计数器持久DCP中数据计数器写请求的减少
全球数据的爆炸增长使得数据中心的数据存储开销日益增加。为了降低数据存储开销,有研究显示,其中大部分数据会转变为访问频率很低的“冷数据”,因此微软Azure在OSD 20I14,提出了通过对数据中心的机架资源(供电,制冷等)进行合理配置的方案(Right-provisioning)。同时,数据去重技术作为被广泛研究和应用的高效降低数据存储量的技术,能否适配到Right-provisioning配置下,使得进一步降低数据中心的存储开销。
信息存储及应用实验室博士生程良锋、研究助理柯兆康,在胡燏翀教授的指导下,设计实现了一种结合数据去重的资源合理配置的冷存储系统(DeCold)。我们发现在微软的Right-provisioning配置下,不同的资源组进行切换时存在8s的延迟,因此为了保证文件的读性能,其将同一个文件放置在同一个资源组(SFSG constrain)。但是传统的数据去重方案采用全局去重,没有“资源组”的概念,因此在Right-provisioning配置下会将同一个文件划分成多个数据块存储到多个资源组,造成多次资源组切换。基于此,我们提出了在线组内去重方案,同时通过合理地分配数据集存储在不同资源组,以提高组内数据去重效率。进一步,我们发现各个资源组之间仍然存在大量相同和相似文件等冗余数据,通过集合分析,我们给出了不同资源组之间进行数据去重时所需要的删除和迁移的具体数据块的集合。基于此,我们提出了离线组间去重,同时我们设计了三种优化方案来提高组间去重的处理效率。在不同的备份数据集下的测试结果显示,DeCold可以在Right-provisioning配置下,相较于组内去重方案的数据去重率提升了87.8%,实现传统去重系统去重率的98.4%,同时保证了文件的读性能。原型系统DeCold已开源https://github.com/yuchonghu/decold。
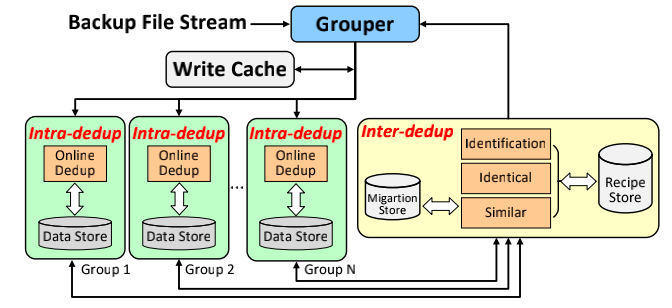
DeCold系统框架

在不同备份数据集下,DeCold和对比系统的数据去重率对比
International Conference on Parallel Processing(ICPP 2021)是中国计算机学会推荐B类会议,此次会议收到的总投稿数为329篇,最终录用87篇,录用率为26.4%。

 分享文章
分享文章